
Architecturae fundamentum est in structura
В этой статье разбираемся, что такое Kafka, зачем используется, плюсы, минусы, подводные камни. На уровне, достаточном для руководителя проекта, так, чтобы понимать, о чём говорят разработчики.
Сначала предлагаю прочесть статью о монолитной и микросервисной архитектуре, потому что Кафка активно связана именно с микросервисной архитектурой.
Штука эта крайне полезная для бэкенд разработки и в современных проектах применяется чрезвычайно часто.
Основные понятия
Если совсем кратко, то в модульной системе есть поставщики сообщений (producers) и получатели сообщений (consumers). И нужно иметь инструмент для управления очередями этих самых сообщений.
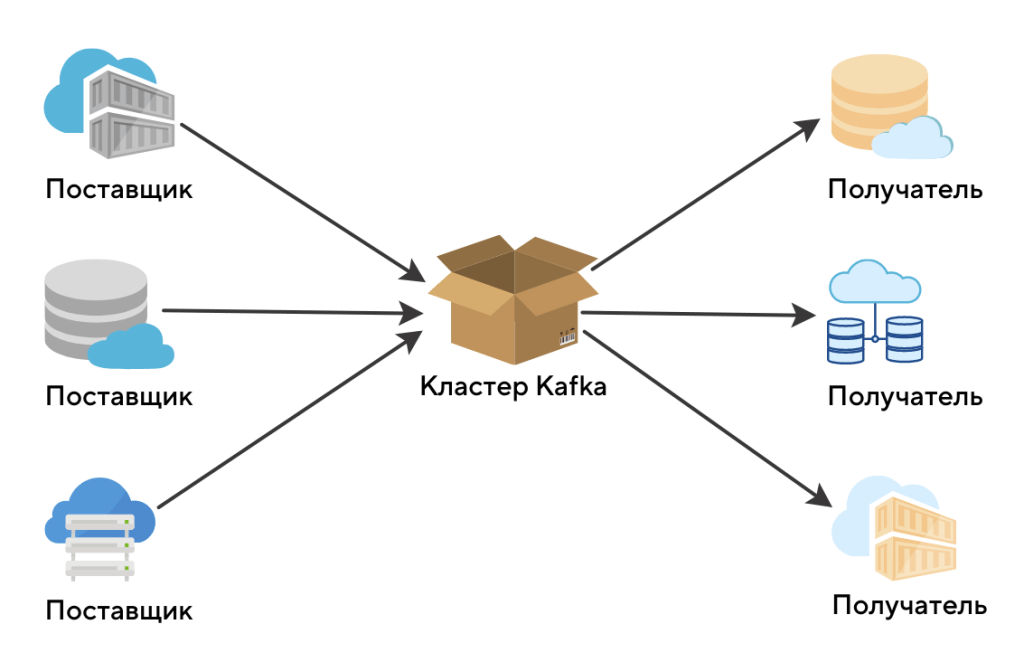
Сообщения могут распределяться между получателями самыми разными способами. Например, первому получателю нужны события только от первого поставщика, второму — только от второго, а третьему — вообще, все сообщения.
Проблемы, возникающие в системах без управления очередями
Одна из проблем, которые тут вылезают — проблема гарантии доставки. Что, если один из получателей перестанет получать сообщения? Если сообщения незначительные, ничего страшного. А если это финансовая транзакция или ещё что-то важное, что должно быть гарантированно доставлено?
Вторая проблема, которая возникает, если не использовать Кафку — сложность подключения новых получателей. Если микросервисов-поставщиков много, задача становится совсем нетривиальной.
Третья проблема — поставщики и получатели могут быть написаны на разных языках программирования и с использованием разных фреймворков, в системе может не быть единого стандартного протокола обмена сообщениями.
Где в мире применяется Кафка
Возможно, самый яркий пример использования Kafka — газета The NY Times, которая все статьи и правки хранит в Кафке. Но есть ещё несколько интересных примеров:
- LinkedIn, социальная сеть для профессионалов, разработала и внедрила Apache Kafka для обработки и передачи событий, в числе которых уведомления о новых связях, сообщения и действия пользователей. Это помогло им обеспечить реактивность и оперативность взаимодействия между пользователями.
- Netflix использует Apache Kafka для стриминга и обработки данных в реальном времени. Они собирают, в основном, разные метрики, делают это для построения персонализированных портретов пользователей и учёта их интересов в рекомендациях.
- Uber использует Apache Kafka для обработки событий, связанных с заказами, платежами и другими операциями на платформе. В этой системе огромное количество данных о заказах должно обрабатываться быстро и надёжно, что Кафка в полной мере и обеспечивает.
- Airbnb применяет Кафку для работы с данными о бронях.
- Twitter использует Apache Kafka для обработки потоков твитов и событий. Да, чтобы вы могли получать инфу о событиях в мире и новых срачах своевременно, тоже нужен брокер сообщений.
- Walmart, крупнейшая розничная сеть в мире, использует Apache Kafka для обработки данных о продажах, инвентаре и покупательском поведении. Это помогает им улучшать управление запасами, анализировать тренды и оптимизировать процессы.
Особенности Кафки
- Kafka умеет работать с высокими нагрузками, переваривая и пересылая огромные объёмы информации. В ней есть все, что нужно для работы с высокими нагрузками: репликация, горизонтальное масштабирование, параллельная обработка потоков сообщений сразу на нескольких серверах в рамках кластера.
- Kafka очень хорошо справляется с задачами перебалансировки нагрузки в случае выхода из строя отдельных компонентов системы.
- Понятная и простая логическая модель разделения микросервисов на поставщиков и получателей сообщений, возможность категоризации микросервисов.
- Для маршрутизации сообщений могут применяться Routing Keys, похожие на те, что используются в RabbitMQ. Но, в отличие от RabbitMQ, Apache Kafka гарантирует порядок доставки сообщений.
Как работает Кафка
Концепция
Кафка умеет забирать сообщения от поставщиков и хранить их в собственном хранилище.
Потребители же сами время от времени «стучатся» в Кафку и «спрашивают», не появились ли для них новые сообщения. И если появились, Кафка им их «отдаёт».
Если потребитель отвалится, ничего страшного не произойдёт, сообщение будет продолжать храниться внутри хранилища Кафки, пока он не придёт в себя и не заберёт его.
При этом подходе общение между микросервисами становится асинхронным, каждый микросервис может работать в том темпе, который позволяют его мощности. Поставщику не нужно ждать реакции всех получателей, он просто отдаёт сообщения в Кафку и забывает о них.
Внутреннее устройство
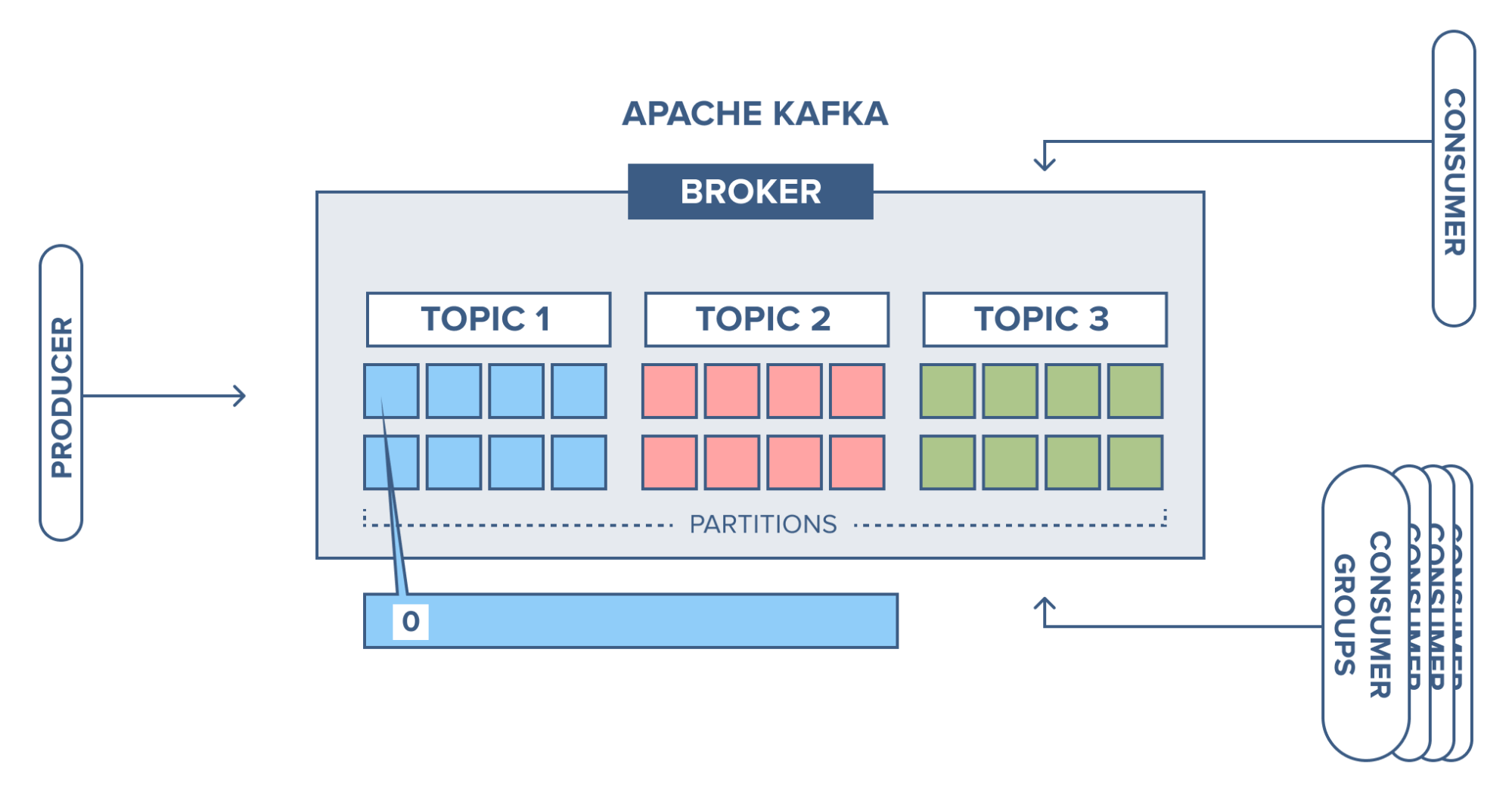
Топики
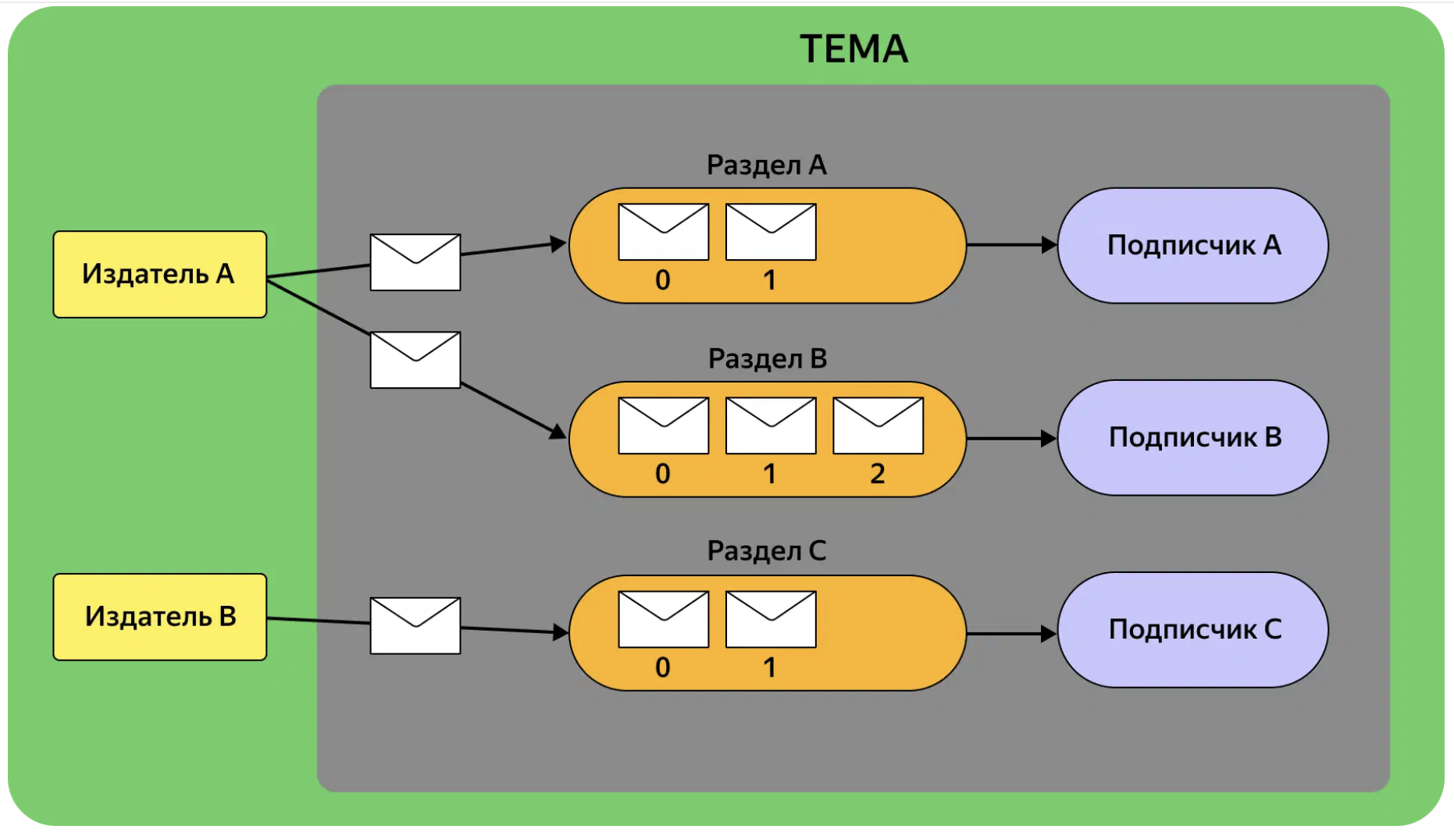
Внутри Кафки сообщения размещаются в топиках. Каждому получателю информации соответствует один или несколько топиков. В целом, топики нужны для логического разделения сообщений.
Получатель забирает сообщения из топика не в рандомном порядке, а строго последовательно.
Offset-ы
Внутри кафки для каждого получателя есть offset, то есть счётчик, показывающий, сколько сообщений получатель прочитал на данный момент. Кафка хранит offset и если получатель отвалился и отсутствовал, например, несколько часов, а потом поднялся и обратился за сообщениями, Кафка знает, начиная с какого сообщения их ему нужно начать выдавать.
Внимание. offset хранится не для топика, а для получателя. Если несколько получателей подписаны на один топик, Кафка знает, сколько сообщений забрал каждый из получателей.
После считывания получателем сообщения из топика, сообщение не удаляется на случай, если другой получатель, работающий в другом темпе, захочет его считать. Есть возможность настроить время жизни сообщений в топиках на усмотрение архитектора.
Разделы (партиции)
Топик может разбивать на разделы (partitions) для облегчения масштабирования. Если у вас есть три получателя сообщений из одного топика, можно настроить параллелизм, разбив топик на три раздела, получателям сообщения будут отдаваться параллельно.
Событие при записи в такой распараллеленный топик будет записываться только в один раздел, в соответствии с настроенными правилами Кафки.
Получатели забирают сообщения из раздела так же, по порядку. Но все разделы обрабатываются параллельно.
Сообщения, соответствующие одному юзер-аккаунту, должны добавляться в один раздел для соблюдения консистентности данных. Технически это реализуется добавлением ключа в сообщение.
Группы получателей
Получатели могут быть объединены в группу, чтобы иметь общий offset. Зачем это нужно, ведь можно просто каждому получателю сделать отдельный раздел, из которого он будет забирать сообщения и всё будет хорошо?
Можно сделать дополнительных получателей. Резервные микросервисы, которые большую часть времени простаивают, но если какие-то из «боевых» микросервисов падают, резервные занимают их место и начинают принимать сообщения из их разделов. Чтобы в этой ситуации не было путаницы, и нужна группа получателей.
Но по правильному, лучше делать соответствие раздел → получатель, один к одному.
Гарантии доставки
В настройках Кафки вы можете указать один из трёх видов гарантий доставки:
- Хотя бы один раз — сообщение может задублироваться, но хотя бы один раз точно будет доставлено.
- Не более одного раза — гарантируется, что дублирования не будет, но есть риск потери сообщения.
- Ровно один раз — более строгая гарантия. Гарантирует, что сообщение доставляется и обрабатывается ровно один раз. Точно не будет ни дублирования, ни потери. Но это самая дорогостоящая с точки зрения ресурсов семантика доставки.
Отказоустойчивость
Кафка может быть запущена в кластере в нескольких экземплярах, которые будут дублировать друг друга и подменять в случае падения одного или нескольких экземпляров.
При этом, на логику поставщиков и потребителей использование кластера никак не влияет, они о дублировании ничего не знают и работают так, как будто Кафка в одном экземпляре.
Когда не стоит использовать Kafka
Не стоит использовать технологии только потому, что они модные, стильные и молодежные. Убежден, что для абсолютного большинства задач в разработке достаточно старой доброй PostgreSQL. Поэтому приведу примеры, когда точно не стоит использовать Kafka:
- Необходима тривиальная база данных для сайта — например, для хранения данных в маленьком интернет-магазине, сделанном на чём-то типа WordPress достаточно будет MySQL.
- Чтение подряд и большими порциями не нужно.
- Нужна настройка каждого сообщения индивидуально.
- Нужны очереди, поддерживающие сложные схемы обработки сообщений (request/reply) — в таком случае лучше использовать готовое решение типа RabbitMQ (у Kafka просто нет такой функциональности из коробки).
Для небольших и простых проектов, без требований к обработке данных в реальном времени, Apache Kafka будет избыточной. Не усложняйте и используйте классическую базу данных или очередь.





