
Memoria celeris, nulla tolerantia defectus
Настоящие олдфаги проектного управления, заканчивавшие российские вузы, по большей части имели дело с реляционными1 БД. Но в современной разработке применяются и нереляционные базы данных. Разбираемся, что такое Редис, простыми словами.
Redis (от англ. remote dictionary server) — резидентная система управления базами данных класса NoSQL, работающая со структурами данных типа «ключ — значение». Используется как для баз данных, так и для реализации кэшей, брокеров сообщений. Изначально выпускалась под свободной лицензией, с 2024 года — под лицензией SSPL
Википедия
Точнее всего описать Redis можно, сказав, что это — сервер структур данных. У него есть особенности, делающие его крайне полезным в проектах некоторых типов, всё это мы рассмотрим в этой статье.
Основная идея заключается в том, что таблицы со строками и столбцами не всегда удобны программисту для работы с данными.
Вместо SQL в таких СУБД используется намного более простой язык запросов Lua.
Редис работает с Докером, прочтите, пожалуйста, мою статью про Кубер и Докер.
Плюсы и минусы
Редис хранит данные в оперативной памяти, что обеспечивает высокое быстродействие, но накладывает риски по целостности.
Данные в Редисе хранятся в виде пар ключ:значение, где ключ — это айдишник, а значение — непосредственно контент.
В целом, Редис нужен там, где нужно высокое быстродействие. Давайте рассмотрим его плюсы и минусы более подробно:
| Плюсы | Минусы |
|---|---|
| Данные быстро записываются и быстро считываются. | Своеобразная работа с транзакциями. Даже если одна операция в серии не выполнится, остальные выполнятся, что может нарушить целостность данных. |
| Крайне прост в использовании. | Есть риск потери данных из-за того, что он хранит данные в ОЗУ. Есть встроенные методы подстраховки от таких сбоев (RDB и AOF) |
| Если нужно обрабатывать большие объёмы данных, Редис отлично масштабируется. | Ограниченность максимального объёма данных объёмом ОЗУ сервера. |
| Поддержка большого количества типов данных. | Слабая работа с реляционными данными. Если ваше приложение должно делать сложные запросы к группам таблиц, лучше выбирать реляционные СУБД. |
| Возможность использования в роли брокера сообщений (читайте мою статью про Kafka) | |
| Большое и отзывчивое комьюнити. Инструмент популярен. |
Конфигурации Редиса
Вообще, выбор конфигурации — не ваша область компетенций, её выбирает техлид или архитектор, им именно за это платят такие космические деньги. Но чтобы вы, в принципе, понимали, что именно они выбрали, давайте разберём, какие конфиги Редиса бывают:
Единственный экземпляр
Конфигурация подходит для небольших проектов. Тупо Редис в единственном числе, один экземпляр, без дополнительной инфраструктуры. Несёт все описанные выше недостатки Редиса — нет восстановления после сбоев и всё такое.
Вариант компактен. При наличии ресурсов серверной мощности, единственный экземпляр Редиса можно развернуть на той же машине, что и основное приложение. Вариант сокращает затраты на конфигурирование.
High Availability (Redis HA)
Основная база работает в тандеме с репликой. Если основная отказывает, реплика становится основной и работает, пока сбой не починят. Чуть выше надёжность, чем у предыдущего варианта.
«Высокая доступность» (HA, High Availability) — это характеристика системы, которая нацелена на обеспечение согласованного уровня показателей её деятельности (обычно — времени безотказной работы системы) на временных интервалах, превышающих средние.
Redis Sentinel
В дополнение к реплике появляются Sentinel-узлы. Они контролируют работу, отслеживают сбои, участвуют в восстановлении системы и указывают, какой из экземпляров базы ведущий. Ещё надёжнее.
Вот какие функции выполняют узлы Sentinel:
- Мониторинг. Обеспечение того, что ведущие и подчинённые узлы работают так, как ожидается.
- Отправка уведомлений администраторам. Система отправляет администраторам уведомления о происшествиях в экземплярах Redis.
- Управление восстановлением системы после отказа. Узлы Sentinel могут запустить процесс восстановления системы после сбоя в том случае, если ведущий экземпляр Redis недоступен и достаточное количество (кворум) узлов согласно с тем, что это так.
- Управление конфигурацией. Узлы Sentinel, кроме того, играют роль системы, позволяющей обнаруживать текущий ведущий экземпляр Redis.
Ещё, для понимания работы этой схемы, нужно разобрать понятие кворума.
Кворум — это минимальное число голосов, которое нужно получить распределённой системе для того, чтобы ей было бы позволено выполнять определённые операции, наподобие восстановления после сбоя.
Статья на Хабре
Это число поддаётся настройке, но оно должно отражать количество узлов в рассматриваемой распределённой системе.
Размеры большинства распределённых систем равняются трём или пяти узлам, в них, соответственно, кворум равен двум или трём голосам. Нечётные количества узлов предпочтительны в случаях, когда системе необходимо разрешать неоднозначности.
Redis Cluster
Самая сложная конфигурация, подходит для приложений, оперирующих большими объёмами данных. Экземпляры Редиса работают как часть кластера, данные распределяются по разным экземплярам. Есть возможность подмены «отвалившихся» узлов и другая балансировка нагрузки.
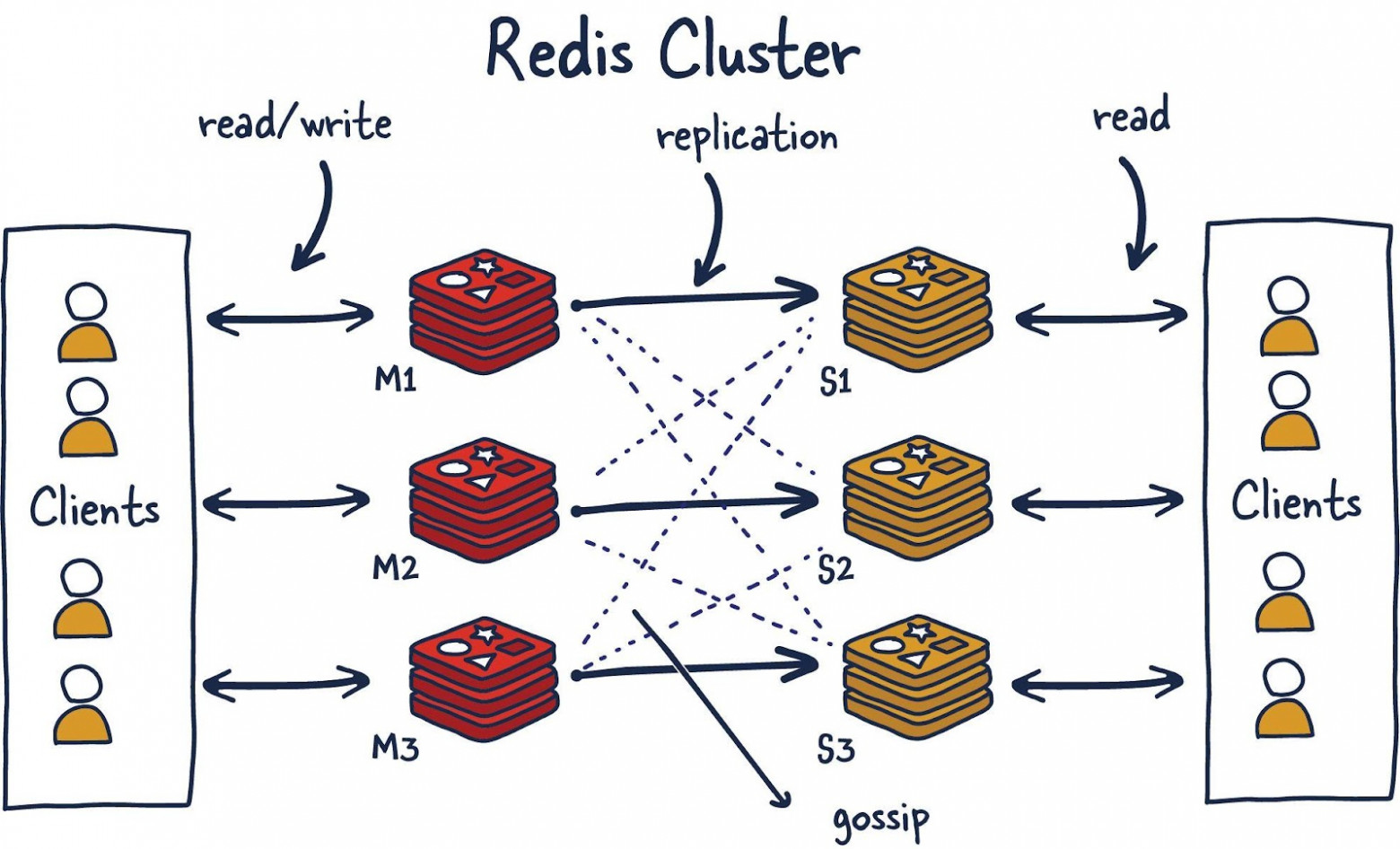
Кластер Redis. Клиенты выполняют операции чтения/записи, взаимодействуя с ведущими (M1, M2, M3) узлами Redis.
Между ведущими и подчинёнными (S1, S2, S3) выполняется репликация данных. Другие клиенты, обращаясь к подчинённым узлам, выполняют операции чтения данных. Для определения общего состояния кластера используется протокол Gossip2.
Поддерживаемые типы данных
- Строки. Тут могут храниться не только классические строки символов, но и бинарные данные, вроде картинок.
- Списки. Примерно то же самое, только несколько штук и в пронумерованном и упорядоченном состоянии.
- Множества. Примерно то же самое, только непронумерованные и неупорядоченные.
- Хэш-таблицы. Набор пар «ключ-значение». Хэши особенно полезны для хранения объектов, например, пользовательских профилей.
- Сортированные множества. Они упорядочены, и у каждого элемента есть числовая метка. Это помогает при сортировке.
- HyperLogLog. Подсчитывает количество уникальных элементов в множестве. HyperLogLog позволяет экономить память при обработке больших объёмов данных.
- Геопространственные индексы. Выполняют операции с географическими координатами. Например, при поиске ближайших объектов.
- Битовые карты. Набор последовательно записанных двоичных разрядов — битов. Битовые карты используют, например, в компьютерной графике, где она хранит значения пикселей.
Но на самом деле, это тоже компетенции техлида-архитектора и немного системного аналитика, вам это всё только для общего развития.
Сфера применения Редиса
- Кэширование. Крайне полезно в нагруженных проектах с большим количеством пользователей, которые одновременно таскают большое количество данных. Веб-сайты, мобильные приложения, игры, всё сюда.
- Управление очередями сообщений. В интернет-магазинах, например, где много заказов и платежей.
- Брокер сообщений. Это полезно там, где нужны уведомления в реальном времени.
- Работа с сессиями. Полезно для организации хранения и использования данных об авторизации пользователей в системе.
- Хранение временных данных. Если вам нужно подсчитать количество посетителей страницы в реальном времени, Редис вам в этом очень поможет.
- Работа с геоданными. Если стоит задача поиска ближайших к пользователю объектов и другие картографические задачи, Редис тоже может быть очень полезен.
- Работа с таблицами лидеров и рейтингами. Полезно в онлайн-играх.
Схема работы Редиса
Давайте рассмотрим на схеме, как работает Редис:
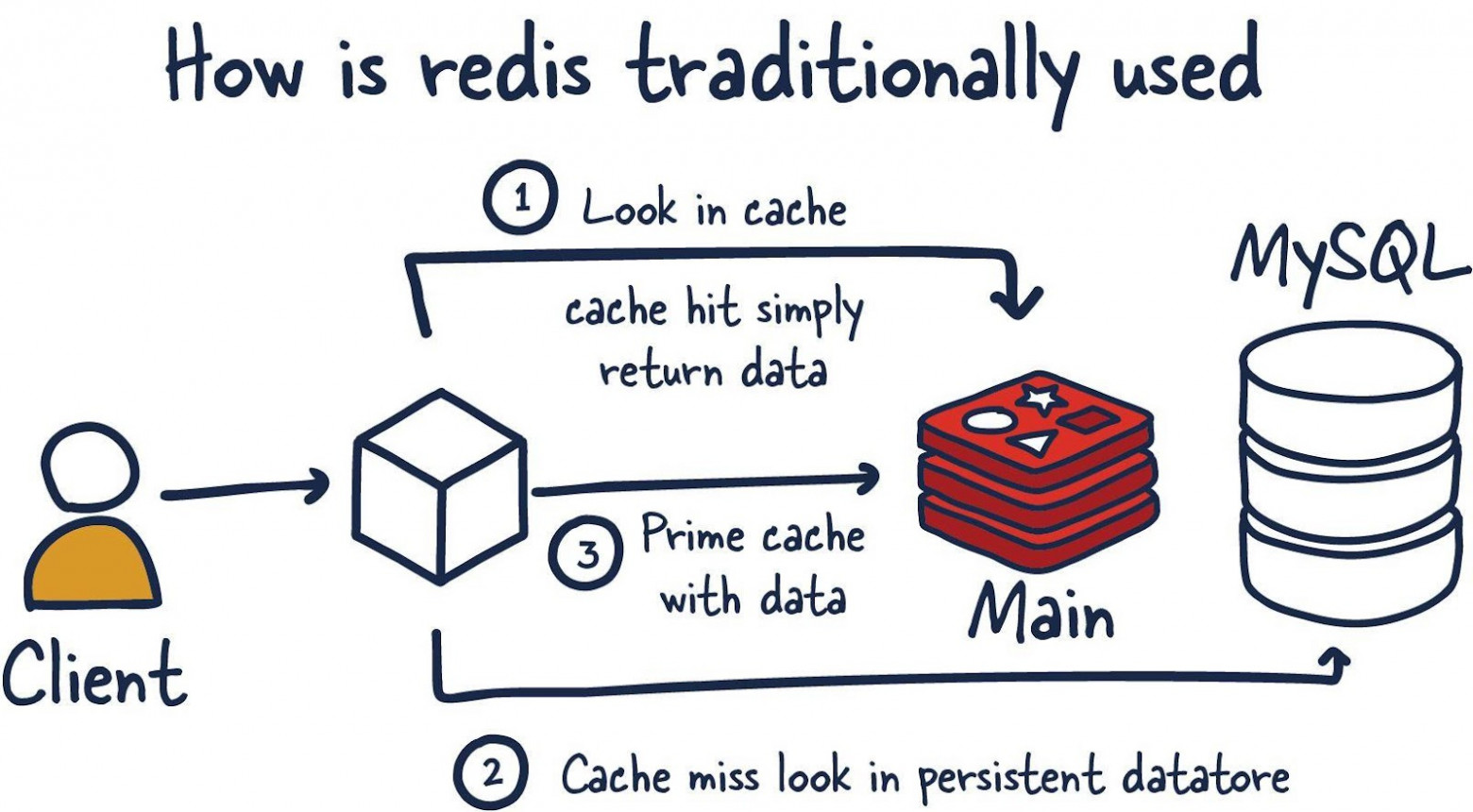
Традиционный подход к использованию Redis выглядит следующим образом: клиент обращается к приложению, а оно получает необходимые для выполнения его запроса данные.
Сначала (пункт 1 на рисунке) приложение обращается к кешу Redis, представленному главной базой данных (Main). Если данные в кеше есть, произошло попадание кеша, выполняется обычный возврат данных.
Если произошёл промах кеша (пункт 2), система обращается к постоянному хранилищу (в данном случае — базе данных MySQL).
Данные из него (пункт 3) загружаются в кеш, после чего ими сможет воспользоваться приложение.
Схема работы Редиса стирает границы между основными данными в БД и кэшем. Работа с данными, находящимися в ОЗУ происходит очень быстро в сравнении с вытаскиванием данных, лежащих на SDD или HDD.
Резервирование
Давайте поговорим об упомянутым выше способам резервирования данных, повышающих стабильность работы редиса.
RDB-файлы
По сути, это снапшоты одномоментных состояний хранилища Редиса. Если произошёл сбой по питанию и мы потеряли данные в ОЗУ, можем восстановить из RDB-файла.
Проблема заключается в том, что эти снапшоты делаются не в каждый момент времени и данные в них могут быть не на 100 % актуальны.
AOF
Это более серьёзное = более медленное резервирование. При этом подходе журналируется каждая операция записи данных в хранилище.
Такой подход к постоянному хранению данных гораздо надёжнее RDB. Ведь речь идёт не о снимках состояния хранилища, а о файлах, рассчитанных только на присоединение к ним данных. Когда происходят операции, их буферизуют в журнале, но они не оказываются сразу после этого размещёнными в постоянном хранилище. В журнале содержатся реальные команды, которые, если нужно восстановить данные, запускают в том порядке, в котором они выполнялись.
В целом, это всё, что руководителю проектов нужно знать о Redis. Это важный компонент распределённой системы, решение о его использовании принимает техлид или архитектор, но вам не будет лишним понимать, что это такое и как работает.
- Реляционная база данных — это тип базы данных, который организует данные в одну или несколько таблиц или отношений. Каждая из них имеет уникальное имя и состоит из набора строк и столбцов.
Данные в реляционной базе данных структурированы и организованы, что облегчает их поиск, извлечение и управление. Обычно они хранятся в нормализованном виде. Данные разбиваются на более мелкие связанные таблицы, каждая из которых имеет свой уникальный ключ или идентификатор. Связи между таблицами определяются с помощью внешних ключей.
Реляционные базы данных широко используются в различных приложениях, включая деловые и финансовые системы, научные исследования и электронную коммерцию. Они обеспечивают гибкий и масштабируемый способ хранения и управления большими объемами данных. ↩︎ - Gossip (сплетник) — это группа протоколов в одноранговой компьютерной коммуникации, в которых распространение информации идёт способом, схожим с образом распространения эпидемий.
Суть протокола сводится к тому, что каждый или некоторые из узлов могут передавать обновляемые данные известным этому узлу соседям.
Некоторые распределённые системы используют такой тип протокола, чтобы обеспечить распространение данных между всеми узлами распределённой системы. В некоторых сетях нет центрального реестра узлов, и использование gossip — единственный способ надёжно распространять между узлами общие данные.
В качестве синонима этого термина также иногда используют словосочетание «эпидемический протокол», имея в виду, что сплетни и вирусы распространяются в обществе схожим способом. ↩︎





